The Autonomous DBA: Building a "Self-Healing" Availability Group
Architecting automated database resilience: How to programmatically intercept Availability Group health states, deploy automated remediation scripts, and safely orchestrate cluster-level self-healing routines without manual intervention.
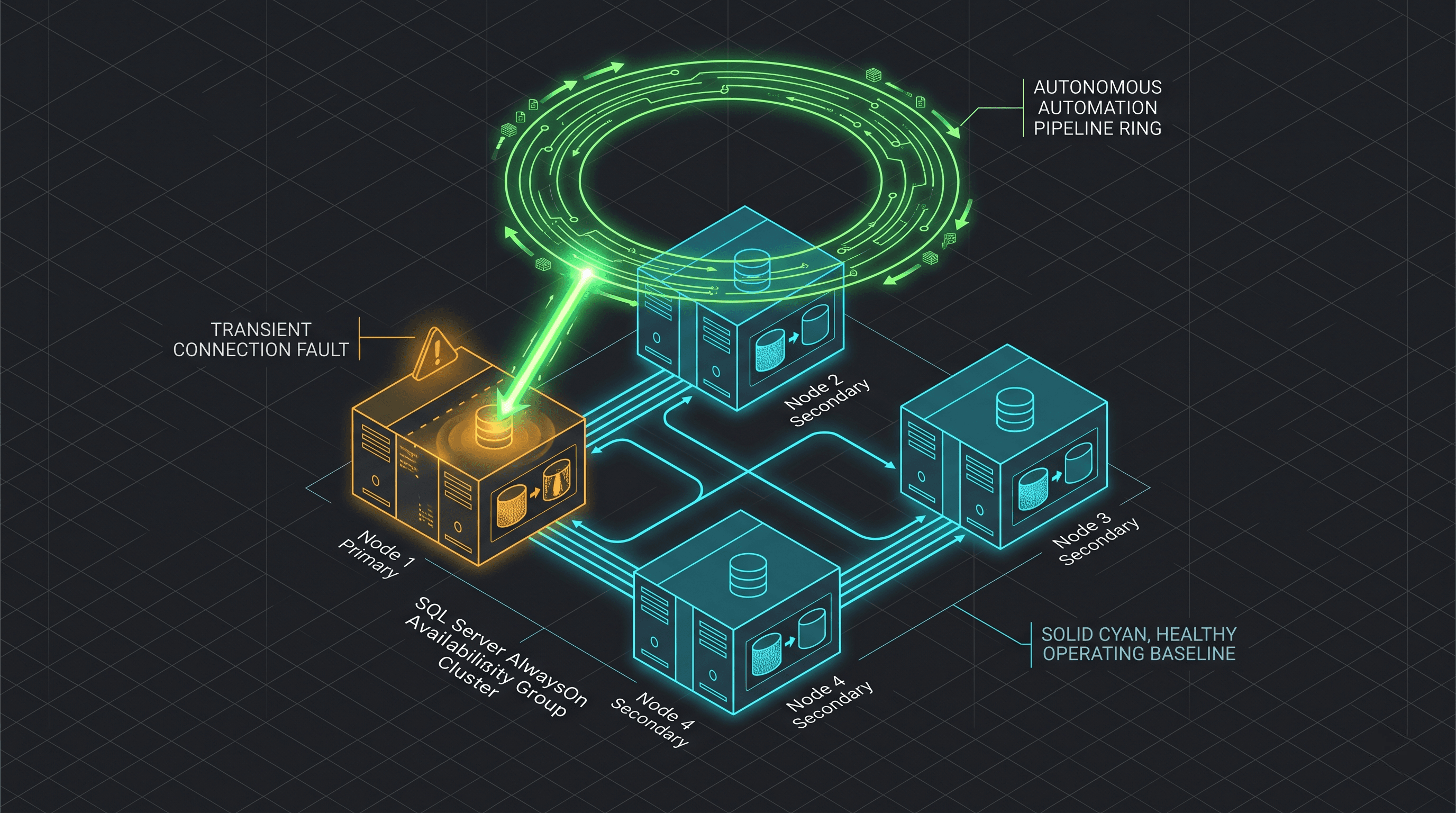
Always On Availability Groups are brilliant at protecting your data from hardware failures, network partitions, and OS crashes. If a node dies, the AG fails over. Simple.
But what happens when an unoptimized UPDATE runs on your largest transactional table at 2:00 PM, taking out a schema modification lock and blocking 400 active customer sessions?
Your AG does absolutely nothing. The cluster is healthy. The disks are fine. But your application is dead in the water.
Traditional database administration dictates waiting for a blocking alert, logging in 15 minutes later, running sp_WhoIsActive, and manually killing the SPID. But in high-throughput environments, we don't have 15 minutes. Today, we are exploring a "Self-Healing" Availability Group—an automated watchdog that detects catastrophic blocking chains, identifies the root blocker, terminates the process, and logs the intervention for a post-mortem analysis.

⚠️ CRITICAL DISCLAIMER: > The architecture described below automates the
KILLcommand in SQL Server. If implemented improperly, or without rigorous filtering, it will cause catastrophic data loss, application outages, or corruption of in-flight business processes. This code is provided for educational and architectural debate purposes only. Do not deploy this in a production environment without extensive testing in lower environments and explicit sign-off from your Change Advisory Board. Use at your own extreme risk.
The Architecture of the Watchdog
Automating process termination is dangerous. If scoped incorrectly, you risk killing background system processes, CDC capture jobs, or critical executive rollups. We need a highly governed, strictly scoped architecture:
The Graveyard: A permanent table to log exactly who was killed, what query they were running, and why.
The Watcher: A T-SQL script that identifies only the head of a blocking chain that has been starving other user processes for more than 5 minutes.
The Executioner: Dynamic SQL that terminates the connection and immediately alerts the DBA team.
Step 1: Build the Graveyard
First, we need a permanent location to log our automated interventions inside our DBA_Master database.
USE [DBA_Master];
GO
CREATE TABLE [dbo].[Automated_Kill_Log](
[LogID] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED,
[KillTime] [datetime] NOT NULL DEFAULT(GETDATE()),
[VictimSPID] [int] NOT NULL,
[VictimLogin] [sysname] NOT NULL,
[HostName] [sysname] NOT NULL,
[DatabaseName] [sysname] NOT NULL,
[BlockedSessionCount] [int] NOT NULL,
[WaitDurationSeconds] [int] NOT NULL,
[RogueQueryText] [nvarchar](max) NULL
);
GO
Step 2: The Executioner Logic
This is the core engine, designed to run in a SQL Server Agent Job scheduled every 1 minute.
This script is incredibly strictly scoped. It will only target a SPID if it meets all of these conditions:
It is a user process (ignores system SPIDs).
It is the absolute head of the blocking chain.
It is currently blocking at least 5 other sessions.
It has been causing waits for over 5 minutes (300 seconds).
USE [DBA_Master];
GO
CREATE OR ALTER PROCEDURE [dbo].[usp_SelfHealing_AutoKill]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @HeadBlockerSPID INT;
DECLARE @VictimLogin SYSNAME;
DECLARE @HostName SYSNAME;
DECLARE @DatabaseName SYSNAME;
DECLARE @BlockedSessionCount INT;
DECLARE @WaitDurationSeconds INT;
DECLARE @RogueQuery NVARCHAR(MAX);
DECLARE @KillCommand NVARCHAR(100);
-- 1. Identify the Head Blocker meeting extreme criteria
WITH BlockingCTE AS (
SELECT
blocking_session_id AS HeadBlocker,
COUNT(*) AS BlockedCount,
MAX(wait_duration_ms) / 1000 AS MaxWaitSeconds
FROM sys.dm_os_waiting_tasks
WHERE blocking_session_id IS NOT NULL
AND blocking_session_id <> session_id
GROUP BY blocking_session_id
)
SELECT TOP 1
@HeadBlockerSPID = b.HeadBlocker,
@BlockedSessionCount = b.BlockedCount,
@WaitDurationSeconds = b.MaxWaitSeconds,
@VictimLogin = s.login_name,
@HostName = s.host_name,
@DatabaseName = DB_NAME(r.database_id),
@RogueQuery = SUBSTRING(t.text, (r.statement_start_offset/2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(t.text)
ELSE r.statement_end_offset
END - r.statement_start_offset)/2) + 1)
FROM BlockingCTE b
INNER JOIN sys.dm_exec_sessions s ON b.HeadBlocker = s.session_id
LEFT JOIN sys.dm_exec_requests r ON s.session_id = r.session_id
OUTER APPLY sys.dm_exec_sql_text(r.sql_handle) t
WHERE s.is_user_process = 1
AND b.BlockedCount >= 5 -- Must be blocking at least 5 sessions
AND b.MaxWaitSeconds >= 300 -- Must have been blocking for 5+ minutes
AND s.session_id NOT IN (SELECT session_id FROM sys.dm_os_waiting_tasks WHERE blocking_session_id IS NOT NULL) -- Proves it is the HEAD of the chain
ORDER BY b.MaxWaitSeconds DESC;
-- 2. If a rogue process is found, terminate it safely.
IF @HeadBlockerSPID IS NOT NULL
BEGIN
-- Log the intervention
INSERT INTO [dbo].[Automated_Kill_Log] (VictimSPID, VictimLogin, HostName, DatabaseName, BlockedSessionCount, WaitDurationSeconds, RogueQueryText)
VALUES (@HeadBlockerSPID, @VictimLogin, @HostName, @DatabaseName, @BlockedSessionCount, @WaitDurationSeconds, @RogueQuery);
-- Execute the kill
SET @KillCommand = 'KILL ' + CAST(@HeadBlockerSPID AS VARCHAR(10)) + ';';
BEGIN TRY
EXEC sp_executesql @KillCommand;
PRINT 'Terminated SPID: ' + CAST(@HeadBlockerSPID AS VARCHAR(10));
-- Alert the DBA Team immediately
EXEC msdb.dbo.sp_send_dbmail
@profile_name = 'DBATeam',
@recipients = 'Rakesh.kishore@hotmail.com',
@subject = 'URGENT: Automated KILL Executed by Self-Healing Watchdog',
@body = 'The Self-Healing AG job has terminated a process. Please review the Automated_Kill_Log in DBA_Master immediately.';
END TRY
BEGIN CATCH
PRINT 'Failed to kill SPID ' + CAST(@HeadBlockerSPID AS VARCHAR(10)) + '. Error: ' + ERROR_MESSAGE();
END CATCH
END
END;
GO

The SRE Debate: Risk Management vs. Uptime
If you pitch this architecture in a standard enterprise CAB meeting, it will face heavy resistance. The immediate argument is always: "What if it kills a critical financial month-end process?"
It is a valid concern. This architecture is not designed for legacy environments where 10-minute blocks are a normal, accepted part of business operations.
This approach belongs in high-throughput, SaaS applications where a database bottleneck causes an immediate total loss of service. In a modern SRE context, you have to weigh the risks. Is it better for a single internal user to receive an error message ("Your query was terminated due to resource constraints"), or is it better to let the entire web application go offline for thousands of active customers while you wait for a human to log in?
Hardening the Script Further
To implement this safely in a hybrid environment, you must build a "White-List" exclusion table into the WHERE clause.
For example, explicitly ignore known, heavy service accounts: AND s.login_name NOT IN ('Domain\ServiceAccount_CDC', 'Domain\Finance_Batch_Process').
Availability Groups provide excellent infrastructure resilience. But combining an AG with an automated, self-healing T-SQL watcher provides true application resilience.
Stop waiting for monitoring alerts to wake you up at 3:00 AM. Give your database the tools to defend its own uptime.