UNION vs. UNION ALL: How Hidden Sort Operators Slow Down Your Combined Datasets
Unmasking the duplicate check penalty: Why combining queries can trigger unexpected disk grinding, how to trace performance plan warnings, and when to drop the distinct filter safely.
When building reports, data pipelines, or backend API lookups, you frequently need to combine the results of two or more separate queries into a single, unified dataset. To make this happen, T-SQL provides two basic operators: UNION and UNION ALL. On the surface, they look almost identical, and in many application scenarios, they return the exact same rows.
Because UNION sounds like the standard, default term, many software engineers write it instinctively whenever they need to stitch statements together.
But as the underlying data expands into millions of rows, using a raw UNION can cause a previously fast dataset query to suddenly drag. When you inspect the execution plan, you find that the database engine is spending 90% of its time processing a resource-heavy Sort Operator, forcing the query to spill into TempDB and slow down transactions. Let's look at the mechanical difference between these two operators in plain language, why one forces a hidden performance penalty, and how to rewrite your scripts to combine data at maximum speed.
1. The Real-World Analogy: Merging the Business Card Collections
To understand why a raw UNION slows down your database, look at how an administrative assistant combines two stacks of customer contact cards collected at different networking events.
The UNION ALL Strategy (Dumping into the Box): Imagine the manager asks the assistant to quickly combine Stack A (5,000 cards) and Stack B (5,000 cards) into a single box. Using the
UNION ALLapproach, the assistant simply picks up both stacks and drops them into the box together. The entire operation takes exactly two seconds. If there happens to be a duplicate card where a customer attended both events, both copies stay in the box. It is lightning-fast and requires zero mental effort.The UNION Strategy (The Forced De-duplication): Now, the manager issues a strict rule: combine the stacks, but ensure there are absolutely zero duplicate cards inside the final box (The Raw
UNIONOperator).The Sorting Nightmare: The assistant can no longer just dump the cards in. To guarantee no duplicates exist, they are forced to clear a massive conference table, lay out all 10,000 cards one-by-one, sort them alphabetically from A to Z, scan the lines side-by-side to find matching pairs, tear up the duplicates, pack the remaining cards back into the box, and clean off the table. This takes hours of exhausting labor, leaving the worker stuck at the desk while other tasks grind to a halt.
In SQL Server, using a raw UNION forces the database engine to run a hidden, memory-heavy sorting operation across your entire dataset to find and delete duplicate rows on the fly, while UNION ALL simply appends the rows instantly with zero processing friction.
2. The Internal Mechanics: The High Cost of the Distinct Sort
When you write a query using UNION ALL, you are telling the query optimizer to perform a basic concatenation. The engine runs Query 1, streams the rows straight to the output buffer, runs Query 2, and streams those rows immediately right behind them. It doesn't care about what data lives inside the columns, and it requires almost no extra memory allocation.
When you switch that operator to a raw UNION, the engine behavior changes completely. A raw UNION carries an implicit DISTINCT command under the hood. To enforce this rule, the query optimizer is forced to insert a Sort (Distinct Sort) operator directly into your execution plan pathway:
Memory Grant Demands: Before the engine can determine if two rows are identical, it must physically sort the entire combined dataset in memory based on every single column listed in your
SELECTstatement.The TempDB Spill Bottleneck: If the combined dataset is too large to fit inside the memory footprint allocated by the optimizer, the engine throws a warning flag. It is forced to spill the rows onto your hard drives inside
TempDB, grinding your query performance down to match your storage disk speeds.
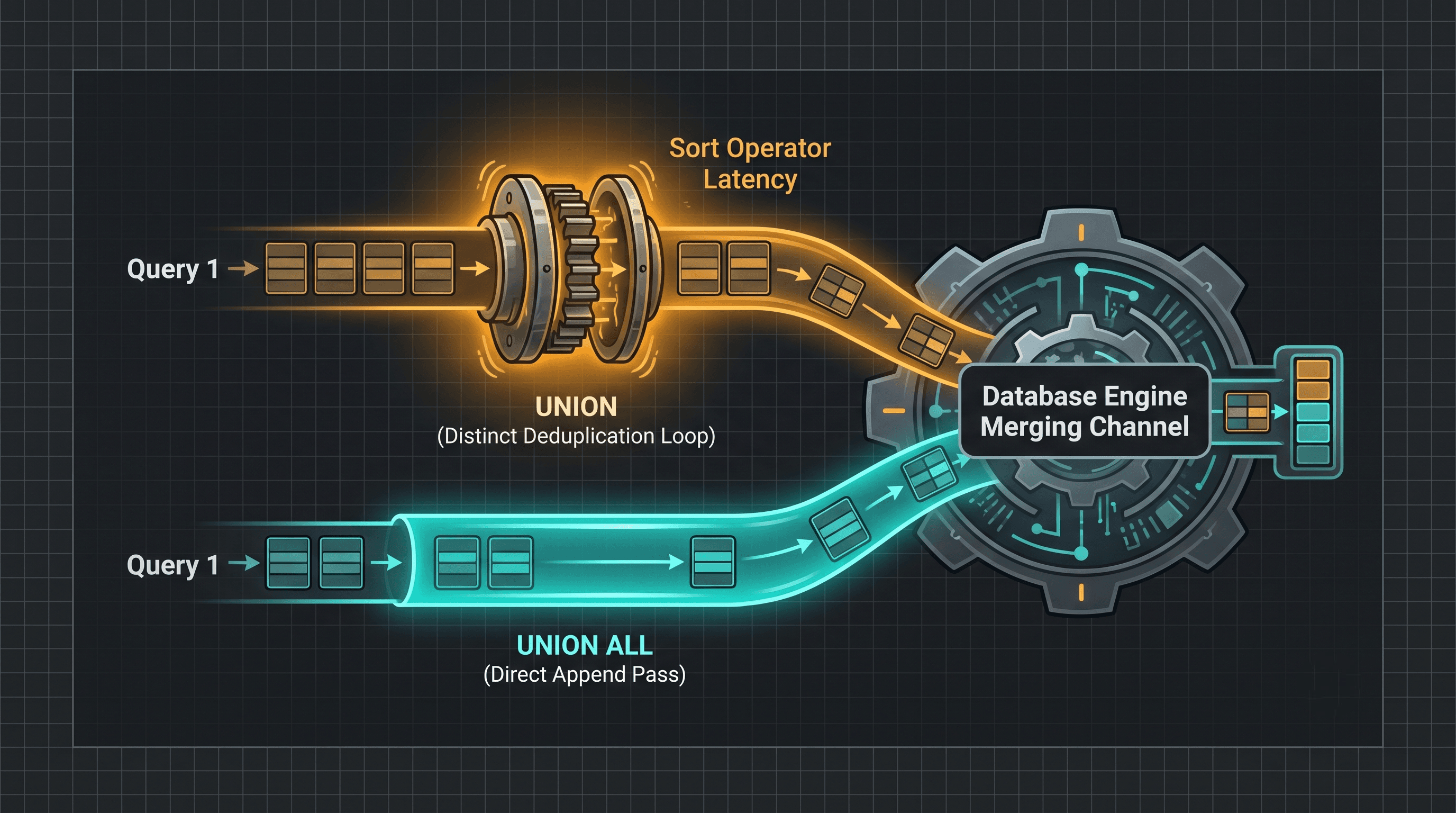
3. Diagram 1: Concatenation Appending vs. The Deduplication Sorting Loop
This architectural diagram maps out how an unoptimized duplicate check interrupts data streaming compared to an instant, linear data append.
[Image showing two data streams appending directly under UNION ALL versus entering an intensive sorting block under a raw UNION operator]

4. Live Triage: Exposing Expensive Sort Operators in Your Cache
Because queries using improper UNION operators run successfully without errors, they can live inside your production codebase for months, quietly burning up memory allocations and driving high disk read metrics. You can look directly inside the server's plan cache to expose these hidden sorting bottlenecks.
Run this plain-language diagnostic script to locate combined queries currently suffering from high sorting costs:
SELECT TOP 5
st.text AS [QueryText],
qs.execution_count AS [Total_Executions],
-- View the total logical page reads (High reads signal heavy data scanning and spills)
qs.total_logical_reads / qs.execution_count AS [Avg_Logical_Page_Reads],
-- View the average CPU processing time spent in clean milliseconds
(qs.total_worker_time / qs.execution_count) / 1000 AS [Avg_CPU_Time_MS],
qp.query_plan AS [ExecutionPlanMap]
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
-- Search specifically for queries containing the raw UNION keyword while avoiding UNION ALL text
WHERE st.text LIKE '%UNION%'
AND st.text NOT LIKE '%UNION ALL%'
AND st.text NOT LIKE '%sys.dm_exec_query_stats%' -- Filter out this troubleshooting script itself
ORDER BY qs.total_worker_time DESC;
GO
If this script highlights queries running thousands of times an hour while racking up massive logical page reads or high CPU execution scores, those are your primary candidates for immediate optimization.
5. How to Optimize Your Queries and Speed Up Dataset Merges
To eliminate hidden sort operator penalties permanently, you must carefully align your query operators to match your actual data distribution requirements.
Step 1: Default to UNION ALL Everywhere
As an absolute baseline rule of thumb for database development, always use UNION ALL by default. Only use a raw UNION if you genuinely expect duplicate rows to appear between your query outputs, and you absolutely require the database to strip them out for reporting accuracy.
Look at this simple structural switch to see how easily you can slash query execution times:
-- BAD APPROACH: Forces a massive distinct sort operator, slowing down the pipeline
SELECT CustomerID, CityCode, TotalSpent FROM dbo.LocalCustomers
UNION
SELECT CustomerID, CityCode, TotalSpent FROM dbo.InternationalCustomers;
GO
-- TUNED APPROACH: Streams data from both tables instantly with zero sorting overhead
SELECT CustomerID, CityCode, TotalSpent FROM dbo.LocalCustomers
UNION ALL
SELECT CustomerID, CityCode, TotalSpent FROM dbo.InternationalCustomers;
GO
Step 2: Leverage Pre-Existing Table Constraints
If you truly need to ensure that no duplicate rows slip through into your application, check if the two datasets originate from tables that are naturally separated by their own design constraints.
For example, if Table 1 only contains active records (IsActive = 1) and Table 2 only contains archived records (IsActive = 0), it is mathematically impossible for a row to exist in both places. In this scenario, running a raw UNION is a complete waste of server resources; you can use UNION ALL with absolute confidence, knowing your results will stay duplicate-free without forcing a distinct sort loop.
6. The Ultimate Dataset Concurrency & Query Optimization Cheat Sheet
For quick reference during a query slowdown, memory pressure spike, or sorting performance triage session, utilize this comprehensive multi-panel architecture dashboard to analyze dataset merge operators, eliminate hidden distinct costs, and maintain maximum streaming throughput safely.

Have you ever tracking down a slow-moving report only to find out that a legacy raw UNION keyword was forcing a massive database sort spill inside TempDB? Did switching the script over to a clean UNION ALL syntax fix your processing lag instantly? Let's talk query performance optimization and dataset tuning strategies in the comments below!