Hidden CPU Burn: How Scalar User-Defined Functions Trap Your Queries in RBAR Loops
Unwrapping row-by-row bottlenecks: Why modular code kills database performance, how to track hidden UDF execution penalties, and how to convert functions into high-speed inline expressions.
When building complex database applications, software engineers naturally want to follow clean coding practices like DRY (Don't Repeat Yourself). If your business logic requires a complex calculation—such as computing a regional tax percentage, calculating an employee tenure bracket, or parsing an encryption string—the cleanest approach is to wrap that logic into a modular, reusable Scalar User-Defined Function (UDF).
Once built, you can call it elegantly inside any query: SELECT CustomerID, dbo.fn_GetTax(ZipCode) FROM dbo.Orders.
It looks like beautiful, object-oriented code. But when you run this query against a table with a few million records, your server's CPU instantly spikes to 100%, and a routine report that should take seconds spins for twenty minutes. Let's look at why scalar functions create massive performance bottlenecks in plain language, how they hide their resource footprints from execution plans, and how to rewrite your code using inline expressions to unlock true parallel processing speeds.
1. The Real-World Analogy: The Interrupted Assembly Line
To understand why scalar functions destroy database performance, look at how a factory worker packages electronic items under two different production strategies.
The Set-Based Strategy (The High-Speed Conveyor): In a healthy database operation, the engine processes data in batches (Set-Based Processing). This is like a conveyor belt moving 10,000 items at 60 mph. A mechanical scanner sweeps across all 10,000 items simultaneously as they fly past, processing the entire batch in a single second.
The Scalar Function Strategy (Row-By-Agonizing-Row): Calling a scalar function inside your
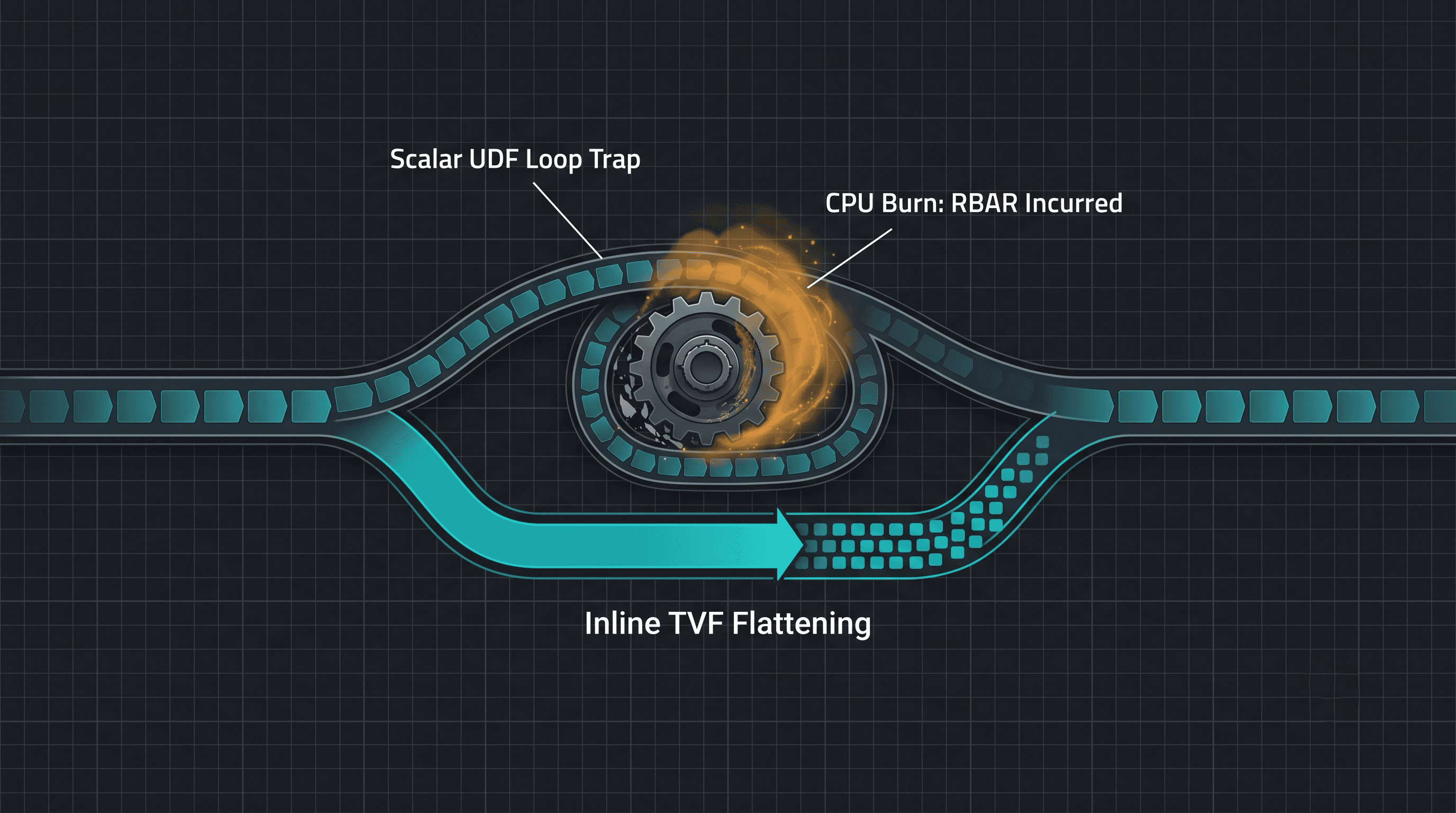
SELECTlist forces the engine into a trap known as RBAR: Row-By-Agonizing-Row.The Assembly Line Meltdown: Imagine an item approaches the worker on the belt. The worker hits a giant emergency stop button, halting the entire conveyor belt. They pick up the item, walk all the way across the factory floor to a locked storage office (The Context Switch), open a manual textbook, look up the custom code rule for that item, write it down, walk back to the line, restart the conveyor belt for exactly one second until the next item arrives, and hit the stop button again. Repeating this walk 10,000,000 separate times leaves the worker exhausted, the factory gridlocked, and production at an absolute standstill.
In SQL Server, a scalar function forces the query engine to halt its optimized set-based processing pipeline, spinning up a separate context switch execution loop for every single row in your table.
2. The Internal Mechanics: The Black Box Plan Trap
Scalar functions are treated as absolute "black boxes" by the traditional SQL Server query optimizer. When the engine builds an execution plan for a query containing a scalar UDF, it cannot see the T-SQL code nested inside the function ahead of time.
This introduces two severe runtime performance penalties:
Context Switching Latency: The database engine has to constantly bounce back and forth between two different computational layers—executing the primary relational query plan, pausing it, spinning up the procedural T-SQL function engine to calculate the row's scalar value, dropping it back, and advancing to the next row.
Parallelism Blockade: Because the engine cannot calculate the total resource cost of the nested black-box function code, it plays it safe. It completely disables parallelism for the entire query, forcing a massive multi-million-row calculation to run on a single, lonely CPU core.
3. Diagram 1: Set-Based Parallel Flow vs. The Scalar Context Switch Loop
This technical processing pathway details how an unoptimized scalar function breaks parallel processing arrays, locking your execution threads into a rigid, slow loop.

4. Live Triage: Uncovering Hidden UDF Execution Costs
Because scalar functions operate inside a separate context execution layer, their true performance penalties do not appear in traditional query execution plan costs. A plan might tell you that a select node takes 0% of the cost, while it is secretly burning up hours of CPU time behind the scenes.
Run this plain-language diagnostic script to look straight into your instance's function execution statistics and expose your true CPU hogs:
SELECT TOP 5
db_name(fs.database_id) AS [Database_Name],
object_name(fs.object_id, fs.database_id) AS [ScalarFunction_Name],
fs.execution_count AS [Total_Row_Calculations_Executed],
-- View total CPU time spent inside this function in clean seconds
fs.total_worker_time / 1000000 AS [Total_CPU_Seconds_Burned],
-- Calculate average processing cost per row in clean milliseconds
(fs.total_worker_time / fs.execution_count) / 1000 AS [Avg_Per_Row_Cost_MS]
FROM sys.dm_exec_function_stats fs
WHERE object_name(fs.object_id, fs.database_id) IS NOT NULL
ORDER BY fs.total_worker_time DESC;
GO
If this script highlights functions that have run millions of times while racking up thousands of total CPU worker seconds, you have successfully isolated a classic RBAR infrastructure bottleneck.
5. How to Flatten Your Code Using Inline Table-Valued Functions (ITVFs)
To eliminate context switching and restore blazing parallel execution speeds, you must upgrade your legacy scalar functions into Inline Table-Valued Functions (ITVFs).
Unlike scalar functions, an inline table function wraps its logic inside a single RETURNS TABLE macro. This allows the SQL Server query optimizer to completely smash the function flat during compilation, injecting the logic straight into the primary query's set-based parallel plan as if you had written the code inline manually.
Step 1: Refactor the Scalar Function into an Inline TVF
Look at this structural transition to see how a slow, loop-trapped scalar function is converted into a high-speed inline architecture:
-- BAD ARCHITECTURE: Scalar UDF forces row-by-row context switching
CREATE FUNCTION dbo.fn_LegacyGetDiscount (
@TotalAmount DECIMAL(18,2)
)
RETURNS DECIMAL(18,2)
AS
BEGIN
DECLARE @Discount DECIMAL(18,2) = 0;
IF @TotalAmount > 1000 SET @Discount = @TotalAmount * 0.10;
RETURN @Discount;
END;
GO
-- TUNED ARCHITECTURE: Inline TVF allows the engine to flatten the math into a parallel plan
CREATE FUNCTION dbo.fn_OptimizedGetDiscount (
@TotalAmount DECIMAL(18,2)
)
RETURNS TABLE
AS
RETURN (
-- Wrapping the logic in a clean, set-based SELECT statement eliminates the black box
SELECT
CASE
WHEN @TotalAmount > 1000 THEN @TotalAmount * 0.10
ELSE 0
END AS DiscountAmount
);
GO
Step 2: Update Your Query Syntax to Use CROSS APPLY
Once your inline function is live, alter your query calling syntax slightly to link the function using the CROSS APPLY operator:
-- BAD APPROACH: Traditional scalar call runs slow row-by-row on a single core
SELECT OrderID, dbo.fn_LegacyGetDiscount(TotalAmount) FROM dbo.Orders;
GO
-- TUNED APPROACH: CROSS APPLY with an Inline TVF executes at blazing parallel speed
SELECT o.OrderID, f.DiscountAmount
FROM dbo.Orders o
CROSS APPLY dbo.fn_OptimizedGetDiscount(o.TotalAmount) f;
GO
6. The Ultimate SQL Server UDF Alignment & Concurrency Cheat Sheet
For quick reference during a high CPU crisis, application slowdown, or query optimization review, utilize this comprehensive multi-panel architecture dashboard to analyze function execution metrics, eliminate black box bottlenecks, and maintain set-based throughput safely.

Have you ever tracking down an insane database CPU spike only to find out a single scalar function was executing a row-by-row context switch loop millions of times a minute? Did refactoring your logic over to an Inline TVF framework drop your processing times instantly? Let's discuss functional database architectures and set-based tuning layouts in the comments below!