It is 3:00 AM on your on-call rotation, and the monitoring alerts start firing relentlessly. A primary production application is throwing connection timeouts, and the error logs point to a critical infrastructure failure: The disk drive hosting your database transaction log (.ldf) has hit 99% capacity and completely run out of space.
When a transaction log balloons out of control, the relational engine immediately halts all data modification operations (INSERT, UPDATE, DELETE) to protect the database from transactional inconsistency. The entire application grinds to a sudden halt.
For a database professional, the natural, panic-induced reaction is to open SQL Server Management Studio (SSMS), right-click the database, and blindly run a heavy SHRINKFILE command over and over again. Stop right there. If you don't understand the root cause of the log expansion, shrinking the file is a temporary band-aid that can trigger massive physical performance degradation known as Virtual Log File (VLF) Fragmentation.
Let's lift the hood on transaction log physical architecture, explore why logs refuse to truncate, and map out the exact script playbook you need to safely reclaim your storage drives during a production emergency.
1. The Real-World Analogy: The Restaurant Order Notepad
To understand why a transaction log behaves the way it does, picture a busy restaurant kitchen managed by an executive chef and a head waiter.
The Data File (.mdf) is the Executive Chef: The chef is responsible for cooking the actual food and organizing the storage pantry shelves. This is an intensive, meticulous job.
The Transaction Log (.ldf) is the Waiter's Notepad: When customers order food, the waiter doesn't make the chef stop what they are doing to update the inventory logs in real time. Instead, the waiter quickly scribbles the orders down chronologically in a notepad. The notepad ensures that if the power suddenly goes out, the kitchen knows exactly which meals were paid for and which ones still need to be cooked.
The Log Truncation is Tearing Out Old Pages: Once the chef finishes a meal and serves it to the table, that line in the notepad is completed. When an entire page of orders is completely served, the waiter can rip that page out of the notepad and throw it away, freeing up space to write new orders.
If the waiter forgets to rip out the completed pages, the notepad will eventually run out of paper. In SQL Server, this is exactly what happens when your log file fills up.
2. Inside the Engine: Virtual Log Files (VLFs)
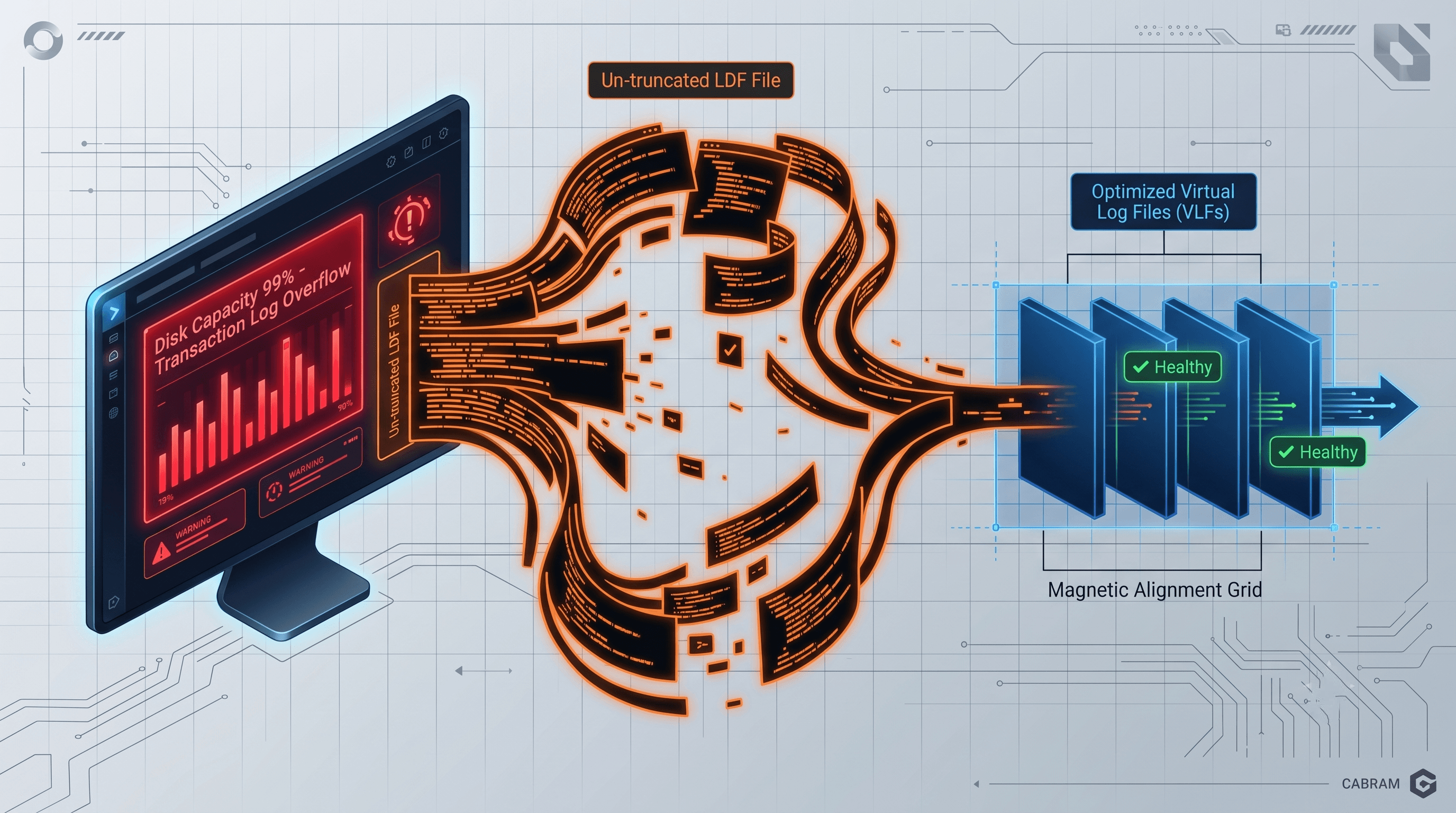
Under the hood, your physical .ldf file isn't just one giant open bucket of text. SQL Server internally segments your transaction log into smaller, hidden logical boundaries called Virtual Log Files (VLFs).
Diagram 1: Understanding Virtual Log Files (VLFs)
Understanding how the engine maps these boundaries internally ensures your recovery pipelines stay un-throttled.

When your application writes data, SQL Server fills these VLFs sequentially. As long as your database is operating healthily, the engine uses Circular Logging: once it finishes writing to the last VLF and a log backup completes, it circles back to the beginning of the file and overwrites the older, inactive VLFs.
However, if an active transaction or a configuration error blocks a VLF from being marked as inactive, the engine cannot circle back. It is forced to physically expand the .ldf file on your hard drive, leading to a runaway log file.
3. The Diagnostics: Finding the Log Truncation Roadblock
When an .ldf file consumes your disk space, your absolute first step is to ask the storage engine exactly what is preventing it from clearing out its inactive VLFs. Do not guess—query the sys.databases system catalog view directly:
SELECT
name AS [DatabaseName],
recovery_model_desc AS [RecoveryModel],
-- The core metric showing why space cannot be reclaimed
log_reuse_wait_desc AS [LogReuseWaitReason]
FROM sys.databases
WHERE name = 'YourDatabaseName';
GO
Decoding the Critical Wait Reasons
When you read the results of the log_reuse_wait_desc column, you will generally hit one of these three enterprise roadblocks:
LOG_BACKUP: This means your database is running in the FULL Recovery Model, but you either haven't configured a scheduled Transaction Log Backup, or your backup agent job is broken. SQL Server will hold onto every single VLF record forever until you run a native log backup to safely archive those records to storage.
ACTIVE_TRANSACTION: A user opened a transaction (e.g., ran a BEGIN TRAN to update an item) and walked away from their desk without executing a COMMIT or ROLLBACK. The log file is trapped; it cannot truncate because it must protect that active, uncommitted change.
REPLICATION or AVAILABILITY_REPLICA: Your high-availability AlwaysOn Availability Group or replication agent is bottlenecked or offline. The primary server is intentionally letting its log file expand because it refuses to delete records until the lagging secondary server confirms it has safely received the data copies.
4. The Emergency Triage Playbook: Reclaiming Disk Space
If your production server is down because the disk is at 100%, follow this exact sequence to restore operations safely:
Step 1: Resolve the Root Roadblock
- If the wait reason is
LOG_BACKUP, immediately execute an adhoc native log backup to trigger log truncation:
BACKUP LOG [YourDatabaseName] TO DISK = 'N:\Safe_Backup_Drive\EmergencyLog.trn';
GO
- If the wait reason is
ACTIVE_TRANSACTION, track down the open session using sys.dm_exec_requests and safely kill the abandoned SPID to free the log hold.
Step 2: Execute a Controlled File Shrink
Once the root roadblock is cleared and the log_reuse_wait_desc returns to NOTHING, the internal VLFs are marked as reusable—but the physical .ldf file on your file system remains bloated. To shrink the physical file size down to a safe operational baseline, use the DBCC SHRINKFILE command targeting the logical name of your log file:
USE [YourDatabaseName];
GO
-- Shrink the physical log file structure down to a target baseline size of 2GB
DBCC SHRINKFILE (N'YourDatabaseName_Log', 2048);
GO
5. The Scheduled Shrink Trap: Why Auto-Shrink is an Anti-Pattern
When struggling with running out of disk space, it is incredibly tempting to turn on the database property AUTO_SHRINK = ON or schedule an unconditioned nightly SQL Server Agent job to run DBCC SHRINKFILE. To an outside observer, automating this seems like an elegant way to keep your storage drives clean.
In reality, implementing an unconditioned automated shrink loop creates a severe performance bottleneck known as the Infinite Shrink-Grow Cycle.
Diagram 2: The Hidden Danger of VLF Fragmentation
This diagram illustrates the cascading destruction of internal log fragmentation caused by cyclic shrinking.

When you force a transaction log to shrink, you are handing space back to the operating system file system. However, if your database executes a massive index rebuild, bulk data import, or heavy reporting batch every week, it physically requires that log footprint to process the transactions.
Because transaction logs cannot leverage Instant File Initialization (IFI), the operating system must physically fill every single new block of disk space with zeros before SQL Server can write to it. The next time that heavy workload fires, SQL Server is forced to pause all user application writes while it waits for the operating system to zero out new disk sectors to grow the .ldf file back to its required size. This causes massive execution timeouts for your users and leaves your log file severely fragmented into thousands of micro-VLFs, crushing your Recovery Time Objective (RTO) during failovers or instance restarts.
The Proactive Alternative: A Conditional SQL Agent Monitoring Job
Instead of a blind, destructive automatic shrink, senior database engineers deploy a conditional response framework.
The following advanced script builds a native SQL Server Agent job. It programmatically checks your real-time transaction log space utilization using sys.dm_db_log_space_usage. It will only trigger a controlled emergency shrink if the log file has ballooned past 20GB and its empty, reusable space exceeds 70%. If those conditions aren't met, it safely skips the operation and logs an audit message:
USE [msdb];
GO
-- Step 1: Create the Maintenance Job Container
DECLARE @JobName NVARCHAR(100) = N'DBA - Conditional Log Space Management';
DECLARE @JobID BINARY(16);
IF EXISTS (SELECT job_id FROM msdb.dbo.sysjobs WHERE name = @JobName)
EXEC msdb.dbo.sp_delete_job @job_name = @JobName;
EXEC msdb.dbo.sp_add_job
@job_name = @JobName,
@enabled = 1,
@description = N'Safely inspects log space limits. Prevents unnecessary shrink-grow performance cycles.',
@job_id = @JobID OUTPUT;
-- Step 2: Embed the Advanced Conditional T-SQL Step
EXEC msdb.dbo.sp_add_jobstep
@job_id = @JobID,
@step_name = N'Evaluate Log Space and Apply Conditional Triage',
@subsystem = N'TSQL',
@command = N'
DECLARE @LogSizeMB DECIMAL(18,2);
DECLARE @SpaceUsedPercent DECIMAL(5,2);
DECLARE @LogicalLogName SYSNAME;
-- 1. Identify the logical internal name of your database transaction log
SELECT @LogicalLogName = name
FROM sys.master_files
WHERE database_id = DB_ID() AND type = 1;
-- 2. Query live space utilization from the storage engine metadata view
SELECT
@LogSizeMB = (total_log_size_in_bytes / 1024.0 / 1024.0),
@SpaceUsedPercent = used_log_space_in_percent
FROM sys.dm_db_log_space_usage;
-- 3. Senior Evaluation Rule: Only shrink if the file is massive AND mostly empty space
IF (@LogSizeMB > 20480.00) AND (@SpaceUsedPercent < 30.00)
BEGIN
PRINT ''CRITICAL CONDITION MET: Log file size is '' + CAST(@LogSizeMB AS VARCHAR(20)) + '' MB with only '' + CAST(@SpaceUsedPercent AS VARCHAR(10)) + ''% space utilized.'';
PRINT ''Executing controlled emergency compaction to preserve OS storage limits...'';
-- Reclaim space safely down to a stable 5GB enterprise baseline footprint
DBCC SHRINKFILE (@LogicalLogName, 5120);
END
ELSE
BEGIN
PRINT ''SYSTEM HEALTH CHECK: Optimal. Log file size is '' + CAST(@LogSizeMB AS VARCHAR(20)) + '' MB with '' + CAST(@SpaceUsedPercent AS VARCHAR(10)) + ''% space utilized.'';
PRINT ''Skipping shrink operation to protect the instance from an infinite shrink-grow bottleneck.'';
END',
@database_name = N'YourDatabaseName', -- Set to your targeted production database
@retry_attempts = 0;
-- Step 3: Schedule the Job to Run Weekly During Low-Traffic Windows
EXEC msdb.dbo.sp_add_jobschedule
@job_id = @JobID,
@name = N'Weekly Sunday Operational Maintenance Window',
@freq_type = 4, -- Daily execution mapping
@freq_interval = 1,
@active_start_time = 020000; -- Fires exactly at 2:00 AM
EXEC msdb.dbo.sp_add_jobserver @job_id = @JobID, @server_name = N'(local)';
GO
6. Proactive Defense: The Proportional Growth Blueprint
To prevent runaway logs and VLF fragmentation from threatening your production environments in the future, implement this definitive infrastructure layout strategy:
Set an Accurate Initial Size: Pre-size your .ldf files generously based on your environment's workload. A great baseline rule of thumb for enterprise OLTP systems is sizing your transaction log to be 25% to 50% of the total size of your main data file.
Enforce Fixed Growth Rules: Never leave your log file's auto-growth setting configured to the legacy default of 10%. If a database grows to 500GB, a 10% growth spike requires the operating system to suddenly allocate 50GB of contiguous disk space instantly, causing massive transaction timeouts. Always configure explicit, fixed-size growth increments:
-- Enforce a clean, predictable infrastructure growth model
ALTER DATABASE [YourDatabaseName]
MODIFY FILE (NAME = N'YourDatabaseName_Log', FILEGROWTH = 1024MB); -- Fixed 1GB steps
GO
By understanding the underlying physics of Virtual Log Files, auditing truncation blocks via catalog metadata, avoiding the automated shrink trap, and setting strict, fixed auto-growth boundaries, you can permanently eliminate unexpected storage outages, minimize VLF overhead, and ensure your production applications maintain elite transaction speeds.
Below is the glimpse of ldf and vlf in a nutshell.

Have you run into an emergency disk space failure caused by a runaway transaction log file? Did a hidden active transaction or a broken backup chain trigger the event? Let's discuss operational recovery tactics and script tuning in the comments below!