SQL Server Implicit Conversions: How to Fix Data Type Mismatches and Stop Slow Index Scans
Stopping the silent query killer: Why matching the wrong data types breaks your indexes, how to find hidden execution plan warnings, and how to align application code.
You spent hours carefully designing a non-clustered index on a massive table's primary lookup column. You verified the query filters match the index key perfectly. Yet, when the application runs the search query in production, the database engine ignores your high-speed index seek path and performs a slow, grinding scan across the entire table, spiking your disk I/O and slowing down transactions.
You open the query execution plan to investigate, and you notice a tiny, easily missed yellow warning exclamation mark hovering over a select node. When you hover your mouse over it, you find a hidden performance warning: CONVERT_IMPLICIT.
An Implicit Conversion is a silent performance killer. It occurs when your application query passes a parameter value whose data type does not match the exact data type of the database table column. Instead of throwing an outright error, SQL Server tries to be helpful by automatically translating the data types on the fly. Let's look at why this auto-translation destroys your index performance in plain language, how to trace these hidden mismatches, and how to align your application frameworks to keep queries running at peak speed.
1. The Real-World Analogy: The Language Barrier at the Border Gate
To understand why data type mismatches slow down your database, look at how a border security checkpoint handles international travellers using two different verification methods.
The Matching Passport (The Fast Index Seek): Imagine an airport gate designed for local residents. A traveller walks up, hands the guard a passport written in the native language (VARCHAR matching a VARCHAR column). The guard reads it instantly in a fraction of a second, stamps it, and the traveller passes through. Traffic moves perfectly.
The Implicit Conversion (The Translation Logjam): Now, a traveller walks up and presents a passport written in a completely different foreign language alphabet (NVARCHAR / Unicode). The local guard cannot read the text. Instead of turning the traveller away, the guard is forced to call an interpreter, translate the foreign text page-by-page into the native language, and then verify the identity.
The Performance Crash: If one person brings a foreign passport, it's a minor delay. But if a tour bus drops off 1,000,000 foreign travellers in a row, the guard must repeat the slow translation process 1,000,000 separate times. The entire border gate gridlocks, lines back up for miles, and no one moves.
In SQL Server, passing an NVARCHAR application parameter to a VARCHAR database column forces the engine to translate every single row in the table one-by-one, completely destroying your index speed.
2. Why Mismatched Types Turn Fast Seeks into Slow Scans
SQL Server follows a strict internal hierarchy known as Data Type Precedence. When a query compares two different data types, the engine will always automatically convert the lower-precedence data type up into the higher-precedence data type before executing the comparison match.
This creates a massive architectural trap when dealing with text fields:
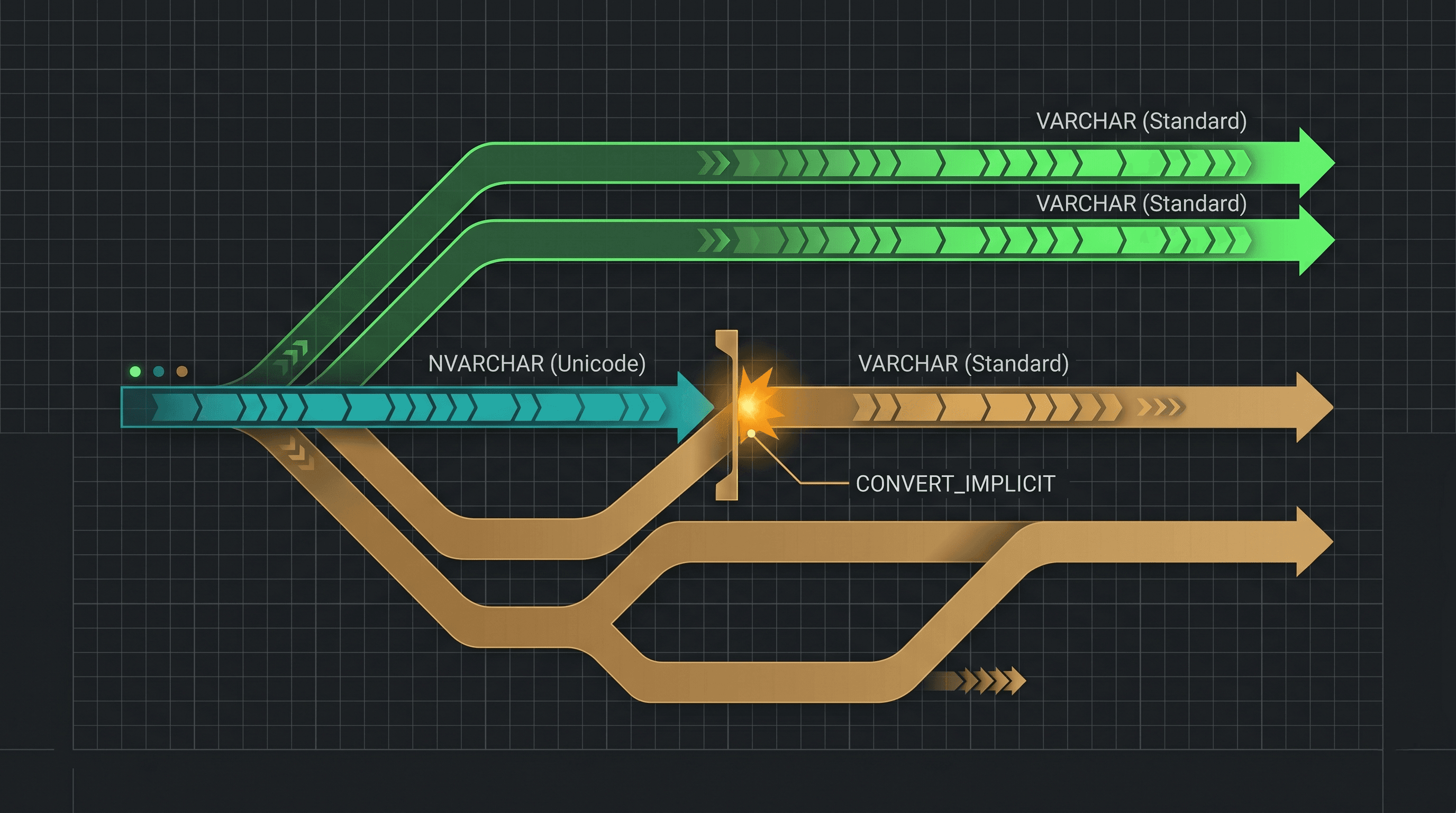
The Precedence Rule: Unicode strings (
NVARCHAR) have a higher precedence than standard text strings (VARCHAR).The Table Scan Trap: If your database column is built as a
VARCHAR(50), and your application code sends the lookup value as anNVARCHARparameter (which is the default behaviour for many modern object-relational mapping frameworks like Entity Framework), SQL Server must convert the table column up to match the incoming parameter.Breaking the B-Tree: Because the engine has to run an internal conversion function on the column itself (e.g.,
CONVERT_IMPLICIT(nvarchar, Column)), it can no longer look at the pre-sorted index tree structure directly. It is forced to abandon the fast index seek and perform a resource-heavy scan across every single page.
3. Diagram 1: Clean Data Type Seek vs. The Mismatch Scan Bottleneck
This engineering layout visualizes how a subtle data type conflict alters the internal query path, breaking a high-speed search and triggering a full-table scan.

4. Live Triage: Catching Hidden Conversions in Your Plan Cache
Because implicit conversions do not generate standard database errors, they can live inside your system for months, quietly burning up CPU cycles. You can look directly inside the server's query execution memory buffers to expose these hidden performance gaps.
Run this plain-language diagnostic script to locate the top queries currently suffering from implicit conversion warnings:
SELECT TOP 10
st.text AS [QueryText],
-- View the raw execution count to see how often the mismatch runs
qs.execution_count AS [HowOftenItRan],
-- Calculate total CPU pressure in clean milliseconds
qs.total_worker_time / 1000 AS [Total_CPU_Time_MS],
qp.query_plan AS [ExecutionPlanMap]
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
-- Safely parse the execution plan XML text to look for the implicit conversion warning flag
WHERE CAST(qp.query_plan AS NVARCHAR(MAX)) LIKE N'%CONVERT_IMPLICIT%'
AND st.text NOT LIKE '%sys.dm_exec_query_stats%' -- Filter out this diagnostic script itself
ORDER BY qs.total_worker_time DESC;
GO
If this script highlights active application queries that run thousands of times a day while racking up massive CPU worker times, those are your primary targets for immediate alignment.
5. How to Align Your Types and Restore Index Performance
Resolving implicit conversion lag requires fixing the data type mismatch so that data verification happens instantly without mid-query translations.
Step 1: Explicitly Define Types in Application Parameter Mappings
If you use object-relational mapping frameworks (like Dapper or Entity Framework) inside your application code, the framework will default to passing string parameters as Unicode (NVARCHAR). You must explicitly tell the framework to use standard AnsiString mapping when calling a standard VARCHAR column:
// BAD APPROACH: Framework defaults to NVARCHAR, triggering a slow table scan
cmd.Parameters.AddWithValue("@CustomerCode", customerCode);
// TUNED APPROACH: Forces the application parameter to match the VARCHAR column perfectly
cmd.Parameters.Add("@CustomerCode", SqlDbType.VarChar, 50).Value = customerCode;
Step 2: Match Variables Inside Your T-SQL Stored Procedures
If you write custom T-SQL stored procedures, ensure the internal variables declared at the top of your scripts match the exact data type properties listed in your table schemas:
-- BAD APPROACH: Variable type conflict forces a conversion function on the table column
DECLARE @SearchInput NVARCHAR(20) = N'TX99';
SELECT AccountID FROM dbo.Orders WHERE OrderCode = @SearchInput; -- OrderCode is VARCHAR
-- TUNED APPROACH: Types match perfectly, enabling an instant index seek
DECLARE @SearchInput VARCHAR(20) = 'TX99';
SELECT AccountID FROM dbo.Orders WHERE OrderCode = @SearchInput;
GO
6. The Ultimate SQL Server Data Type Alignment & Conversion Cheat Sheet
For quick reference during a query slowdown or performance triage session, utilize this comprehensive multi-panel architecture dashboard to analyze data type precedence maps, isolate hidden plan warnings, and enforce clean application parameter bindings.

Have you ever seen a beautiful non-clustered index get completely bypassed by the query optimizer because of a hidden data type mismatch? Did updating your application's connection parameters restore your index seeks instantly? Let's talk code optimization and query tuning tips in the comments below!