When it comes to execution performance, database management systems are fundamentally designed to protect applications from slow storage hardware. Disk operations, even on cutting-edge enterprise NVMe solid-state drives, are orders of magnitude slower than reading directly from local memory buffers.
To maximize throughput, the SQL Server storage engine is highly aggressive with its RAM allocation strategy. By default, it will systematically consume nearly all available operating system memory to cache data pages, execution contexts, and metadata maps.
To an outside observer or a system administrator, a database server sitting at 98% RAM utilization looks like a critical infrastructure failure. To an experienced data professional, it represents an engine operating exactly as designed.
However, memory is a finite playground. If poorly written ad-hoc queries saturate your data buffers or bloat your execution cache, the engine drops into heavy physical disk thrashing. Let's trace the internal architecture of SQL Server memory nodes, evaluate performance tracking counters, and build automated defensive strategies against cache eviction loops.
1. The Real-World Analogy: The Chef's Kitchen Worktop
To bridge the gap between high-level application code and bare-metal memory tracking, look at how an elite restaurant kitchen manages its physical layout.
The Hard Drive (The Deep Freezer): The freezer is located down the hall. It contains all the ingredients (data pages) the restaurant owns. Retrieving something from the freezer takes a significant amount of time and effort.
The Buffer Pool (The Main Kitchen Countertop): This is the large, physical workspace right in front of the chef. When a recipe calls for an ingredient, the kitchen assistant runs to the freezer, grabs the item, and unpacks it directly onto the counter. The chef can now cut, mix, and access that ingredient instantly.
Memory Pressure (Running Out of Counter Space): If the countertop becomes completely covered in unorganized plates and old cutting boards, the chef has no room to execute new orders. The assistant is forced to grab a plate currently sitting on the counter and run it back to the freezer just to clear a few inches of workspace for the next dish.
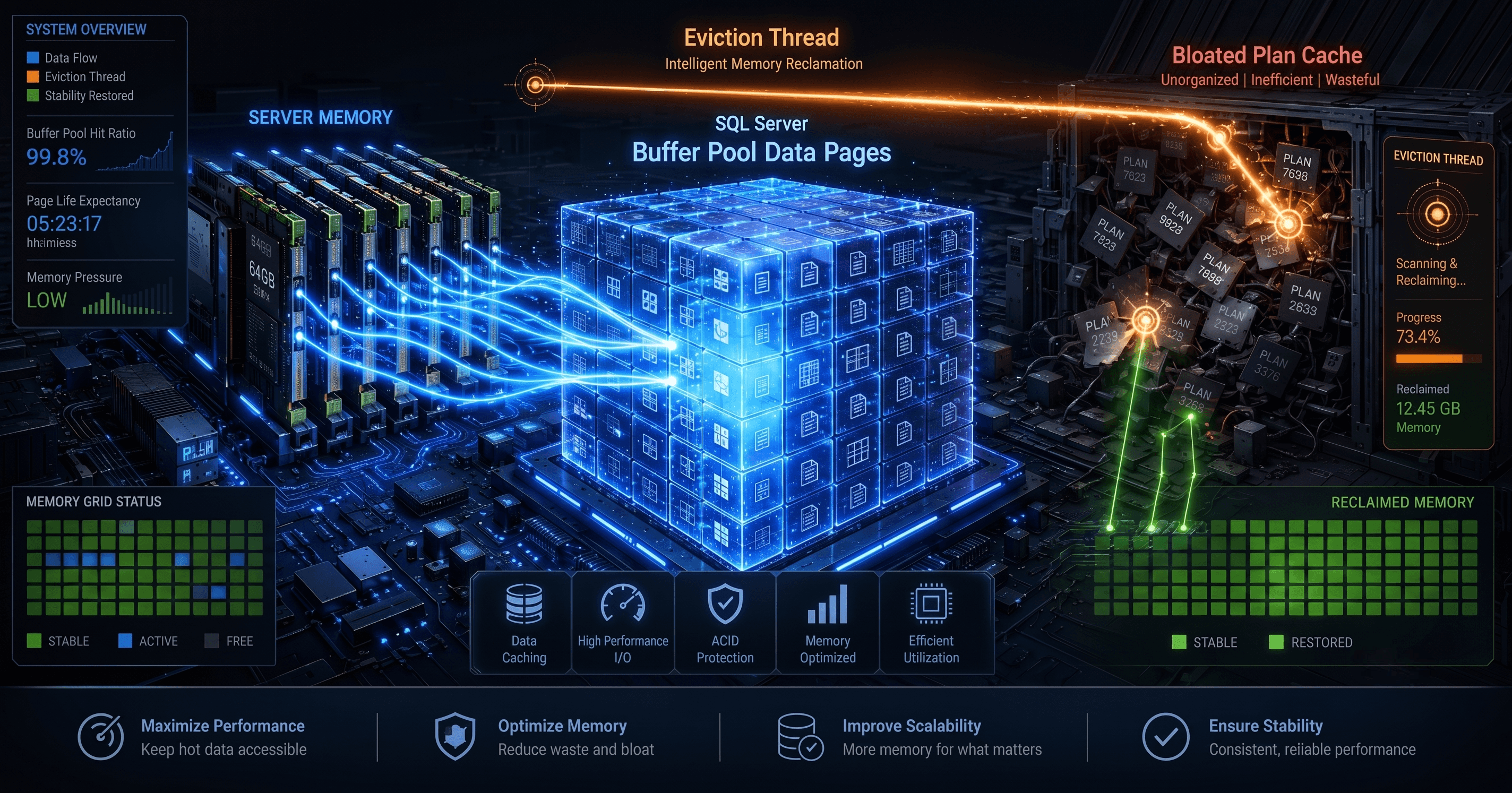
In database systems, this constant, frantic shuffling between the countertop and the freezer is called Buffer Pool Churn.
2. The Internal Hierarchy: Buffer Pools and Memory Clerks
SQL Server coordinates its internal RAM footprint via a highly structured component system managed by the SQLOS layer. The entire memory allocation ecosystem is divided into distinct execution buckets called Memory Clerks.
Every major component inside the database engine—whether it is the query compiler, the security audit pipeline, or the high-availability synchronization engine—must request a dedicated memory clerk to track and bound its specific RAM footprint.
The two most prominent memory allocations you will manage are:
MEMORYCLERK_SQLBUFFERPOOL (The Data Cache)
This is typically the largest memory asset on your server. It hosts the 8KB data pages and index structures read from your database files. It keeps the data alive in RAM so subsequent user SELECT queries can fetch records without hitting the underlying disk storage.
MEMORYCLERK_SQLPLANCACHE (The Logic Cache)
Every time you execute a T-SQL query, the Query Optimizer parses the text, calculates selectivity math, and outputs an optimized execution plan map. Compiling a plan consumes significant CPU cycles.
To prevent repetitive mathematical overhead, the engine saves these generated maps inside the Plan Cache. The next time an identical query runs, the engine bypasses the compilation phase and reuses the existing plan.
3. The Gold Standard Diagnostic: Page Life Expectancy (PLE)
How do you know if your database engine is experiencing critical memory starvation? You inspect a primary performance counter called Page Life Expectancy (PLE).
Page Life Expectancy records a rolling metric indicating the average number of seconds an 8KB data page remains sitting untouched inside the Buffer Pool before it is forcefully evicted to make room for new data incoming from disk.
-- Querying live OS performance counters to track internal memory lifecycle metrics
SELECT
object_name AS [CounterCategory],
counter_name AS [MetricName],
cntr_value AS [PageLifeExpectancy_Seconds]
FROM sys.dm_os_performance_counters
WHERE object_name LIKE '%Buffer Manager%'
AND counter_name = 'Page life expectancy';
GO
The Mathematics of Modern PLE Evaluation
For decades, legacy documentation stated that any PLE value above 300 seconds (5 minutes) was completely healthy. This static baseline is a major pitfall for modern database architectures.
The 300-second rule was calculated back when standard production servers only hosted 4GB of total system RAM. If you are running a modern enterprise server with 512GB of RAM allocated to the Buffer Pool, a PLE of 300 means your server is completely flushing and reloading its entire memory buffer space every 5 minutes. That represents an ongoing, catastrophic I/O storm.
To calculate a true, hardware-aligned target baseline for your modern enterprise infrastructure, apply this proportional scaling formula:
$$\text{Target PLE Baseline} = \left( \frac{\text{Allocated Buffer Pool RAM in GB}}{4} \right) \times 300$$
Under this architectural rule, a production instance hosting 64GB of buffer pool memory requires a baseline PLE value of at least 4,800 seconds to be considered stable and healthy. Anything lower indicates your storage drive channels are actively being saturated by avoidable page thrashing.
4. Unmasking the Villain: Plan Cache Bloat
A major catalyst for low Page Life Expectancy on highly active transactional servers is Plan Cache Bloat. This performance anomaly occurs when developers construct application database queries using direct string concatenation rather than explicit parameterization:
-- The Developer Anti-Pattern: Triggers a unique plan compilation for every distinct value
SELECT * FROM dbo.Customers WHERE CustomerID = 10452;
SELECT * FROM dbo.Customers WHERE CustomerID = 88291;
Because the literals are hardcoded into the query text strings, the SQL Server parser views these as two completely different statements. It is forced to compile two separate execution plans and save both unique maps inside the Plan Cache.
If your application executes millions of these unique ad-hoc statements daily, your MEMORYCLERK_SQLPLANCACHE will rapidly balloon out of control, consuming gigabytes of system memory. To satisfy this aggressive plan cache expansion, the SQLOS engine will automatically steal memory space directly away from your Buffer Pool, evicting healthy data pages to make room for useless, single-use query plans.
5. Enterprise Diagnostics: Auditing Your Memory Clerks
Run this production-grade triage script to identify exactly which internal engine components are capturing your instance's physical memory footprint:
SELECT TOP 5
mc.type AS [MemoryClerkType],
-- Convert baseline internal pages into a human-readable Megabyte footprint
CAST((mc.pages_kb / 1024.0) AS DECIMAL(18,2)) AS [ClerkSize_MB],
-- Track memory allocations across Non-Uniform Memory Access (NUMA) hardware architectures
mc.memory_node_id AS [NUMA_NodeID],
-- Identify if the memory is actively tracking data pages or query execution plans
CASE mc.type
WHEN 'MEMORYCLERK_SQLBUFFERPOOL' THEN 'Data Cache (Main Storage Buffers)'
WHEN 'MEMORYCLERK_SQLPLANCACHE' THEN 'Plan Cache (Query Execution Strategies)'
WHEN 'MEMORYCLERK_SQLGENERAL' THEN 'Internal Engine Core Operations'
ELSE 'Other System Sub-System Allocation'
END AS [FunctionalDescription]
FROM sys.dm_os_memory_clerks mc
ORDER BY mc.pages_kb DESC;
GO
If this script returns a result where MEMORYCLERK_SQLPLANCACHE is trailing closely behind or outpacing your MEMORYCLERK_SQLBUFFERPOOL, your instance is actively wasting valuable computing power on repetitive query compilations.
6. The Proactive Defense Playbook
To mitigate memory pressure and protect your database instance from sudden data cache eviction loops, implement a two-step infrastructure optimization blueprint:
Step 1: Enable "Optimize for Ad Hoc Workloads"
Instead of letting single-use, non-parameterized query paths immediately pollute your system memory, activate the instance-level configuration framework optimize for ad hoc workloads.
USE master;
GO
EXEC sp_configure 'show advanced options', 1;
RECONFIGURE;
GO
-- Instructs the engine to only cache a tiny "Plan Stub" on a query's first execution
EXEC sp_configure 'optimize for ad hoc workloads', 1;
RECONFIGURE;
GO
When this property is enabled, the first time an ad-hoc query strikes your database engine, SQL Server allocates a microscopic 300-byte Plan Stub inside the cache rather than compiling a full, heavy execution map.
If the exact same query text string is executed a second time, the engine recognizes the stub, confirms the query is frequently reused, compiles the complete execution plan, and overwrites the stub. If the query never runs again, the tiny stub is seamlessly evicted with zero impact on your main Data Buffer Pool memory space.
Step 2: Flush Single-Use Waste Programmatically
If your server is already experiencing plan cache bloat during a high-concurrency production cycle, do not run a dangerous DBCC FREEPROCCACHE command. Running a blanket cache clear will wipe out all execution plans across your entire instance, forcing every business-critical reporting tool and API connection to re-compile its queries simultaneously, triggering massive CPU spikes.
Instead, execute a targeted, conditional flush that isolates and removes only the single-use ad-hoc garbage from your cache:
-- Target and purge ONLY the single-use plan waste, preserving your high-value compiled plans
DBCC FREESYSTEMCACHE ('SQL Plans');
GO
By accurately calculating your modern hardware-aligned Page Life Expectancy baselines, isolating memory clerk distribution allocations via real-time DMVs, and activating defensive caching configurations, you protect your instance from plan cache bloat, stabilize your memory boundaries, and keep your business data safely cached for maximum performance throughput.
How do your primary production environments handle memory allocation tracking? Have you configured your high-capacity instances to leverage optimized ad-hoc caching constraints to preserve your data buffers? Let's discuss memory optimization and internal telemetry in the comments below!