When a business-critical database query experiences performance degradation, the most common remediation step is to inspect the table’s indexes. However, there is a massive structural gap between simply having an index on a table and having the optimal index strategy engineered for your workload.
In enterprise relational engines, data access efficiency is entirely dictated by physical B-Tree traversal. If your non-clustered indexes are built without considering column selectivity, prefix matching, or data density, the SQL Server Query Optimizer will frequently abandon your indexes entirely or trigger costly operational traps like the Key Lookup.
For database administrators and senior developers, index design is a balancing act. Every index you add to accelerate a SELECT statement simultaneously adds operational overhead to every INSERT, UPDATE, and DELETE operation executed against that table. Let's pull back the curtain on advanced B-Tree page alignment, master the mathematics of composite column ordering, and look at how to build perfectly covered queries.
1. The Real-World Analogy: The Multi-Volume Corporate Phone Book
To understand how a composite (multi-column) index operates inside the storage engine, look at how a classic physical phone directory organizes information.
The Primary and Secondary Keys: A phone book is sorted strictly by LastName first, and then by FirstName.
The Left-to-Right Rule (The Index Prefix): If you open the phone book to find "Smith, John", you can navigate straight to the "S" section, then to "Smith", and instantly locate the exact line. The index works perfectly because your search criteria match the physical sorting order of the book.
The Index Scan Failure: Now imagine you are handed the exact same phone book, but you are asked to find everyone whose first name is John. Because the book is physically sorted by last name first, the fact that it is alphabetized provides zero benefit. You are forced to flip through every single page from cover to cover to read every first name.
In database internals, this is the exact difference between an Index Seek and a full Index Scan caused by an incorrect column order.
2. The Mechanics of Composite Key Column Ordering
When designing a composite index (an index containing more than one key column), the order in which you define the columns inside your T-SQL statement is critical.
-- Plan A vs Plan B: The order of the keys alters everything
CREATE NONCLUSTERED INDEX IX_Workload_PlanA ON dbo.Orders (CustomerID, OrderDate);
CREATE NONCLUSTERED INDEX IX_Workload_PlanB ON dbo.Orders (OrderDate, CustomerID);
To determine which column belongs on the far left (the leading edge of the index), you must calculate the Selectivity of the data. Selectivity is a mathematical ratio of distinct values against the total row count of the table:
$$Selectivity = \frac{\text{Count of Distinct Values}}{\text{Total Rows in Table}}$$
The closer the selectivity value is to $1.0$, the more unique the data is, and the faster it can narrow down a search space.
The Leading Edge Rule
As a standard architectural principle, always place your most selective columns on the far left of your composite key array. If CustomerID has 100,000 unique values and OrderDate only has 365 unique values (representing days of the year), placing CustomerID first allows the engine to eliminate 99.9% of the table pages in its very first B-Tree leaf seek step.
3. Diagram 1: Left-Based Prefix Matching vs. Scans
This diagram illustrates how SQL Server can gracefully traverse a composite index when using the leading key, but drops into a scan when the leading edge is missing from the query predicate.

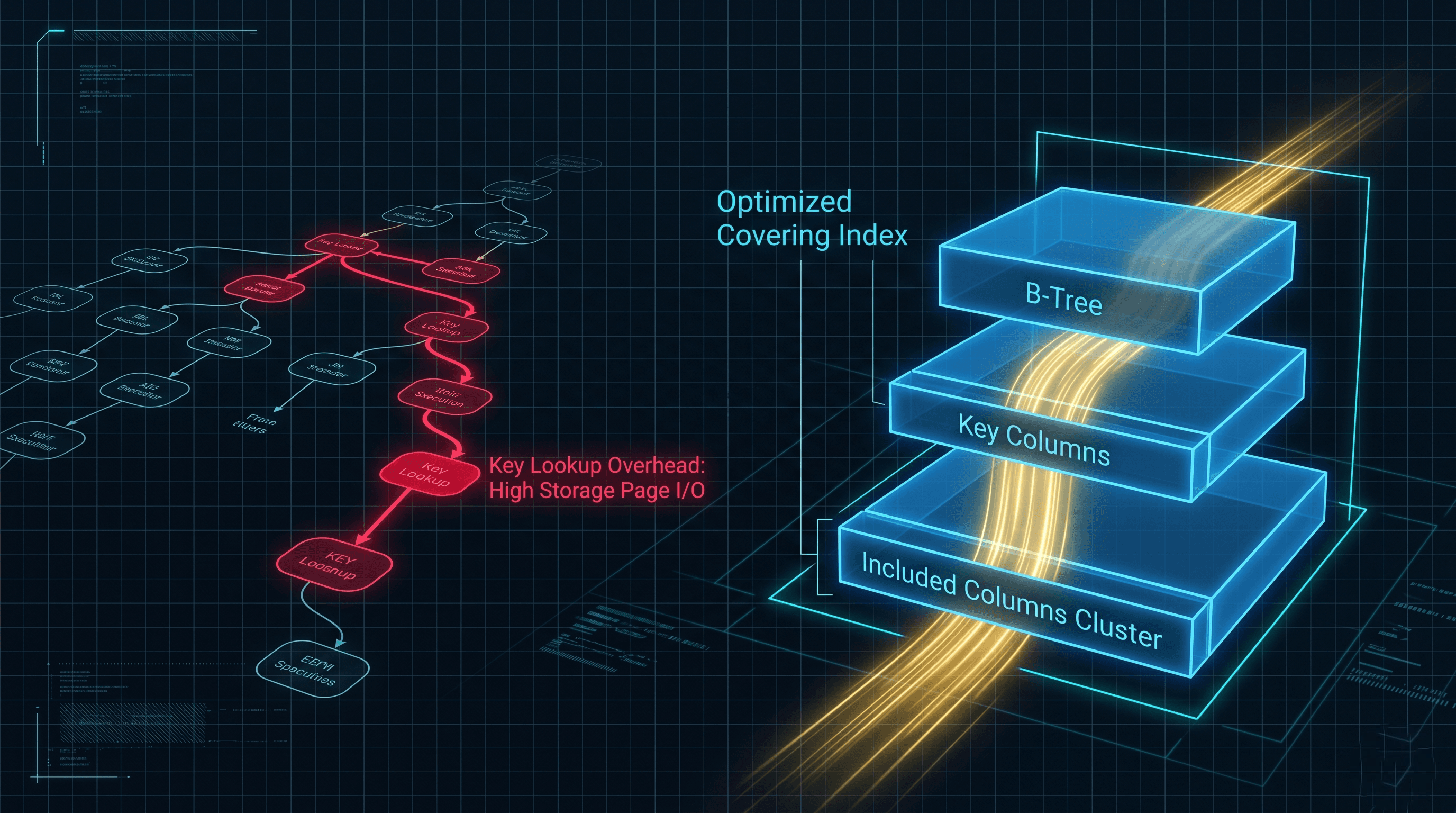
4. Eradicating the Key Lookup via Covered Queries
One of the most expensive operators you can encounter inside an execution plan is a Key Lookup (or an RID Lookup on a heap table).
A Key Lookup occurs when your non-clustered index successfully locates the rows matching your WHERE clause filter, but your SELECT statement requests extra columns that do not physically reside inside that non-clustered index's B-Tree structure.
To fulfill the query request, the engine must halt execution, leave the non-clustered index page, and perform a completely separate read operation against the underlying Clustered Index (the primary key storage) to fetch those missing columns. This second lookup occurs once for every single row returned by the initial index match. If a query returns 50,000 rows, your server will perform 50,000 independent lookup reads, hammering your storage array and memory buffers.
5. Diagram 2: Anatomy of a Key Lookup Failure
This visualization tracks the physical tracking path of an un-covered query as it forces the engine to toggle back and forth between independent index disk locations.

The Fix: Utilizing the INCLUDE Clause
To eliminate this look-up loop, you must create a Covering Index. By utilizing the INCLUDE clause, you tell SQL Server to append the missing data columns strictly onto the leaf level pages of the non-clustered index. These columns do not participate in the sorting or tree-shaping logic of the index keys, which prevents index bloat while completely satisfying the query's data requirements.
-- Unoptimized Index: Triggers a Key Lookup if the query selects OrderTotal or ShippingAddress
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_Unoptimized
ON dbo.Orders (CustomerID)
WITH (FILLFACTOR = 80);
GO
-- Optimized Covering Index: Eliminates the Key Lookup completely
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_Covered
ON dbo.Orders (CustomerID)
INCLUDE (OrderTotal, ShippingAddress)
WITH (FILLFACTOR = 80, ONLINE = ON);
GO
By adding OrderTotal and ShippingAddress to the INCLUDE clause, the non-clustered index now contains all information required to fully satisfy the query. The Query Optimizer can fulfill the request directly from the non-clustered leaf pages, transforming a heavy Key Lookup into a highly efficient Index Seek.
6. Auditing the Overhead: Detecting "Zombie" Indexes
While covering queries is excellent for read performance, over-indexing will cripple your database's write performance. Every time an application inserts a row into a table, SQL Server must physically write that data to the main clustered index and update every single non-clustered index hosting that column layout.
Senior database administrators regularly audit the instance to locate "Zombie" indexes—indexes that are continually updated during write modifications but have never once been scanned or sought by a user query.
Run this enterprise script to identify underutilized indexes across your current database context:
SELECT
OBJECT_NAME(s.object_id) AS [TableName],
i.name AS [IndexName],
i.index_id AS [IndexID],
-- Tracks maintenance costs (Writes)
s.user_updates AS [Total_DML_Writes],
-- Tracks workload benefits (Reads)
(s.user_seeks + s.user_scans + s.user_lookups) AS [Total_Workload_Reads],
s.user_seeks AS [User_Seeks],
s.user_scans AS [User_Scans],
s.user_lookups AS [User_Lookups],
-- Calculate the precise cost/benefit delta
(s.user_updates - (s.user_seeks + s.user_scans + s.user_lookups)) AS [Write_Cost_Delta]
FROM sys.dm_db_index_usage_stats s
JOIN sys.indexes i ON s.object_id = i.object_id AND s.index_id = i.index_id
WHERE s.database_id = DB_ID()
AND OBJECTPROPERTY(s.object_id, 'IsUserTable') = 1
-- Isolate indexes that have been written to at least 1,000 times but rarely or never read
AND s.user_updates > 1000
AND (s.user_seeks + s.user_scans + s.user_lookups) < 50
AND i.is_primary_key = 0 -- Exclude primary keys from triage
AND i.is_unique = 0 -- Exclude unique enforcement constraints
ORDER BY [Write_Cost_Delta] DESC;
GO
If this script returns an index showing 1,500,000 user_updates but 0 user_seeks, that index is actively draining your transaction log throughput, contributing to buffer pool churn, and increasing your backup window sizes for zero business value.
Coordinate with your application engineering teams, record a baseline snapshot, and safely DROP the dead weight to restore write performance back to your transactional storage pipelines.
How do you evaluate multi-column indexes when balancing reporting workloads against high-velocity OLTP write patterns? Have you encountered catastrophic Key Lookup loops on massive enterprise tables? Let's discuss indexing physics and DMV analytics in the comments below!