Cloud Governance: How to Hunt Database Waste and Build Automation Frameworks
Engineering cost-efficient cloud data infrastructure: How to programmatically isolate orphaned database resources, right-size over-provisioned clusters, and deploy automated resource-scheduling governance frameworks.
When you transition from managing physical on-premises servers to cloud platforms like Azure or AWS, your primary responsibility shifts. On-premises, your hardware is already paid for; your only goal is maximizing performance. In the cloud, however, resource consumption maps directly to a live corporate credit card.
For a Junior DBA, writing fast queries is only half the battle. If you can walk into an enterprise cloud environment, identify thousands of dollars in hidden waste, and safely automate infrastructure cost reduction by 30% without dropping performance, you become an invaluable asset to senior leadership.
Cloud cost governance isn't about starved performance—it is about efficiency. Let's break down where cloud database budgets leak, map out automation architectures, and deploy scripts to find underutilized cloud databases.
1. The Real-World Analogy: The Leased Office Building
Imagine your company leases a massive 10-story corporate headquarters.
Over-Provisioning: You pay for all 10 floors every single month, but your development team only sits on Floor 1. The other 9 floors remain completely empty, yet you are paying full rent for them 24/7.
The Weekend Waste: At 6:00 PM on Friday, everyone goes home for the weekend. However, the lights, heating, and air conditioning continue blasting at 100% capacity in the empty building all day Saturday and Sunday.
The Zombie Storage Units: Employees leave the company but keep paying monthly fees for off-site storage lockers filled with old, broken keyboards and empty boxes that the business forgot existed.
In the cloud world, this is exactly how companies burn through engineering budgets. Let’s map out these leaks visually.
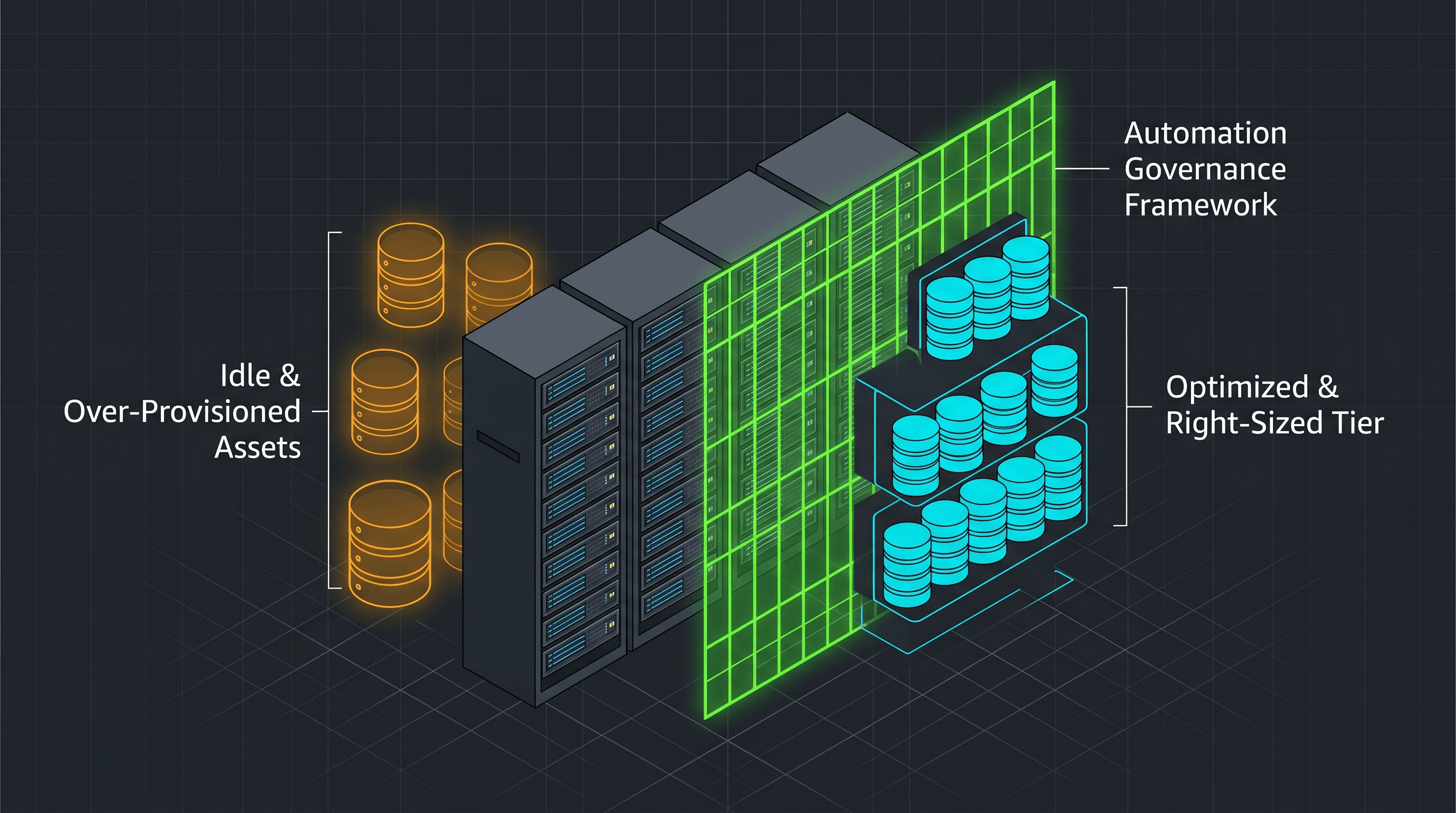
2. Diagram 1: The Cloud Database Waste Landscape
Understanding where money leaks out of an infrastructure profile allows a database administrator to systematically clean up an enterprise environment.

3. Hunting the "Zombie" Resources
Before touching a single live production database, a junior engineer can achieve immediate cost victories by hunting down abandoned infrastructure artifacts.
Orphaned Storage Volumes
When you delete a cloud database virtual machine, the cloud provider does not automatically delete the attached storage drives (VHDs or EBS volumes) to protect you from accidental data loss. If you don't clean them up manually, those disks sit in your subscription completely unattached, quietly billing your company every single month.
Runaway Snapshot Retention
Taking daily manual storage snapshots of a database during a migration or upgrade is a great safety net. However, if your team does not implement an automated lifecycle policy to purge those snapshots after 14 days, they accumulate indefinitely. Over a year, abandoned snapshot volumes can easily grow to outsize the cost of the actual running database.
4. Automation Framework: Finding Underutilized Cloud Databases
To find out which cloud databases are over-provisioned (paying for way more horsepower than they actually use), you have to audit their historical compute metrics over time.
If you are running Azure SQL Databases or Managed Instances, the cloud engine continuously tracks performance metrics inside the master database. Run this script to scan the last 14 days of resource utilization and instantly isolate databases whose average CPU consumption never crosses a low threshold:
-- Run against the master database to detect low-utilization candidates
SELECT
database_name AS [DatabaseName],
MIN(start_time) AS [MonitoringPeriodStart],
MAX(end_time) AS [MonitoringPeriodEnd],
CAST(AVG(avg_cpu_percent) AS DECIMAL(5,2)) AS [AverageCPU_Percent],
CAST(MAX(avg_cpu_percent) AS DECIMAL(5,2)) AS [PeakCPU_Percent],
CAST(AVG(avg_data_io_percent) AS DECIMAL(5,2)) AS [AverageDataIO_Percent],
CAST(AVG(avg_log_write_percent) AS DECIMAL(5,2)) AS [AverageLogWrite_Percent]
FROM sys.resource_stats
WHERE start_time >= DATEADD(DAY, -14, GETDATE())
GROUP BY database_name
-- Filter for databases averaging less than 5% CPU over a two-week window
HAVING AVG(avg_cpu_percent) < 5.0
ORDER BY [AverageCPU_Percent] ASC;
The Junior DBA Remediation Action
If a database shows a peak CPU of only 8% and an average of 1% over a two-week period, it is an ideal candidate for downsizing. Work with your application team to lower its service tier (e.g., dropping from a Business Critical 8-vCore instance to a General Purpose 2-vCore instance), instantly saving the company hundreds of dollars a month on that single resource.
5. Elastic Scaling: Automating the Non-Production Lifecycle
One of the most powerful strategies for cloud optimization is implementing automated elastic schedules for your Development, Staging, and Testing environments.
Development teams generally work a standard business schedule. There is no architectural reason for a Development database instance to run at full power at 3:00 AM on a Sunday.
6. Diagram 2: The Elastic Scaling Automation Framework
By building an automation job using tools like Azure Automation Runbooks or AWS Lambda, you can schedule your cloud environment to dynamically match human work schedules.

By deploying an automated scaling framework, your environment operates with variable efficiency:
The Monday Morning Spin-Up: At 7:00 AM on Monday, an automated cloud runbook fires, scaling the Development instance up to its standard operating tier right before the engineering team logs online.
The Friday Night Drawdown: At 7:00 PM on Friday, the runbook fires again, dropping the database compute allocation down to the lowest possible tier or pausing it entirely.
Implementing this simple operational framework means you only pay for your non-production computing resources for roughly 50 hours a week instead of all 168 hours, instantly cutting your non-production compute bill by over 60%.
7. Storage Tiering: IOPS vs. Capacity
The final pillar of cloud database governance is understanding how cloud providers price storage. Storage cost is driven by two metrics: Capacity (how many gigabytes you store) and Provisioned IOPS (Input/Output Operations Per Second—how fast you can read and write to the disk).
Junior administrators often scale up their storage allocation solely because they need more speed (IOPS). However, this is an expensive way to solve a performance bottleneck.
Before paying for an ultra-high performance premium disk tier, apply the core performance tuning frameworks we mastered in our earlier architectural phases:
Optimize your queries to reduce logical reads.
Maintain your B-Tree index fragmentation and implement appropriate Fill Factors.
Fix underlying relational bottlenecks like Parameter Sniffing to keep execution plans efficient.
By tuning the code layer to use less disk activity, you can safely drop your provisioned infrastructure tiers down to a standard, cost-effective storage layer, achieving elite system performance without blowing your infrastructure budget.
How does your organization balance cloud database performance against monthly expenditure costs? Do you utilize automated runbooks to pause your non-production development tiers over weekends? Let's talk cloud governance in the comments below!